DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
For Barn
Tenk deg et supersmart dataprogram som lærer å løse oppgaver! Det er litt som å lære en hund triks med godbiter. Dataprogrammet får “belønning” for riktige svar, og blir flinkere til å tenke over tid. Dette programmet heter DeepSeek-R1.
Det er viktig fordi det hjelper oss å lage bedre dataprogrammer, både raskere og billigere. Tenk på det som å lære gangetabellen – istedenfor å pugge alt på en gang, lærer DeepSeek-R1 det litt etter litt, akkurat som du lærer det gradvis. Dette betyr at datamaskiner kan bli mye smartere snart, og hjelpe oss med masse forskjellige ting! Det hjelper til og med datamaskinene å sjekke sitt eget arbeid – akkurat som du dobbeltsjekker leksene dine. Selv om det fortsatt lærer, viser DeepSeek-R1 hvordan datamaskiner kan bli enda bedre til å løse problemer – en skikkelig hjerne-knuse-gjennombrudd!
For Videregåendeelever
Tenk deg at du kunne lært en datamaskin å tenke som en detektiv, løse komplekse gåter og puslespill. Det er akkurat det forskerne har gjort med et nytt, supersmart dataprogram som heter DeepSeek-R1! Dette programmet, en type «stor språkmodell» (LLM), er designet for å være ekstremt god på resonnering.
Tradisjonelt har det vært mye jobb å lære LLMer å resonnere – som å vise dem hauger av eksempler på korrekt resonnement. Dette er både tidkrevende og dyrt. Forskerne bak DeepSeek-R1 prøvde en annen tilnærming: de brukte en metode som kalles «forsterkningslæring». Det er som å lære en hund et triks med godbiter – datamaskinen får «belønninger» for riktige svar og lærer å resonnere bedre over tid.
Først bygde de en enklere versjon, DeepSeek-R1-Zero, som kun lærte fra disse belønningene, uten noen tidligere eksempler. Den gjorde det overraskende bra og viste imponerende evner, som å sjekke sitt eget arbeid. Men den skrev noen ganger svar som var vanskelige å forstå.
For å fikse dette, skapte de DeepSeek-R1. Denne forbedrede versjonen brukte en smart, trinnvis treningsprosess. Først fikk den en liten «head start» med noen nøye utvalgte eksempler. Deretter lærte den gjennom belønninger, med en ekstra bonus for klare og lettfattelige svar. Til slutt ble den finjustert (fikk noen flere eksempler for å perfeksjonere ferdighetene).
DeepSeek-R1 presterte nesten like bra som noen av de beste eksisterende LLMer i tester av resonneringsevne – innenfor matematikk, koding og sunn fornuft! De klarte også smart å krympe DeepSeek-R1s kunnskap til mindre, raskere programmer, og viste at det er mulig å ha kraftige resonneringsevner uten å trenge enorme mengder datakraft.
Denne forskningen er en stor greie fordi den viser en ny, mer effektiv måte å bygge LLMer som er flinke til å resonnere. Hele prosjektet er åpen kildekode, som betyr at andre forskere kan bruke og forbedre det – og bane vei for enda smartere datamaskiner i fremtiden! Forskerne erkjenner imidlertid at DeepSeek-R1 fortsatt har noen svakheter, som å være sensitiv for hvordan spørsmålene er formulert, noe som gjør det til et område som trenger videre forbedring.
For Universitets- og Høyskolenivå
Denne forskningsartikkelen introduserer DeepSeek-R1, en ny stor språkmodell (LLM) designet for å forbedre resonneringsevnen gjennom forsterkningslæring (RL). Forskningen tar for seg utfordringen med å forbedre LLMers resonneringsevne uten å være sterkt avhengig av overvåket finjustering (SFT), en beregningsmessig kostbar og dataintensiv prosess.
Artikkelens sentrale forskningsspørsmål er: Kan ren forsterkningslæring effektivt kultivere overlegen resonneringsevne i LLMer uten behov for omfattende overvåket finjustering? For å besvare dette utviklet forskerne to hovedmodeller:
-
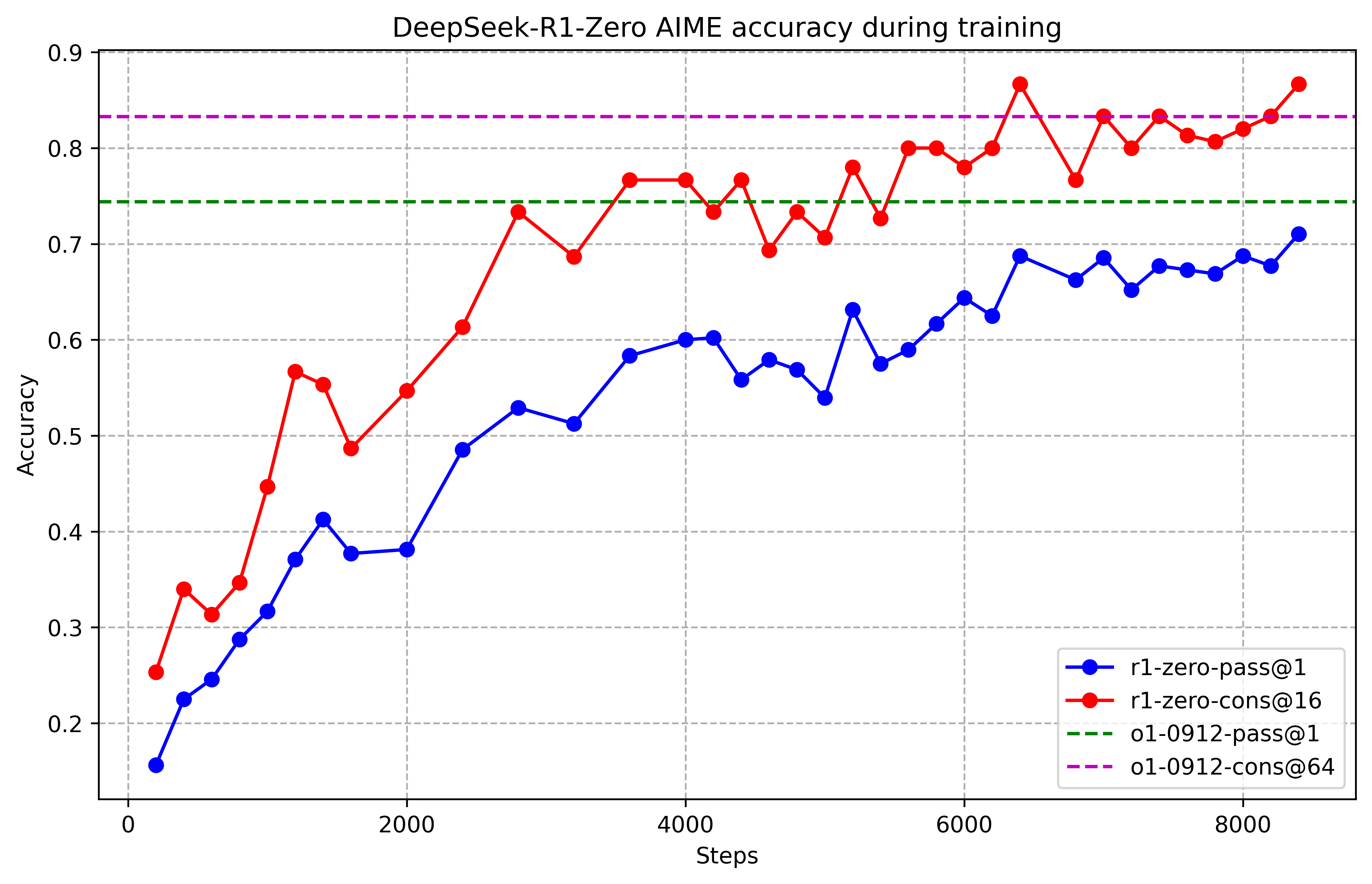
DeepSeek-R1-Zero: Denne modellen trenes ved hjelp av storskala RL uten noen forutgående SFT. Metodikken benytter Group Relative Policy Optimization (GRPO)-algoritmen, en kostnadseffektiv RL-tilnærming som unngår behovet for en beregningsmessig kostbar kritikkmodell. Belønningsmodellen er regelbasert, med fokus på nøyaktighet og utdataformat. DeepSeek-R1-Zero demonstrerer bemerkelsesverdige resonneringsatferdstrekk, inkludert selvverifisering og refleksiv tenkning, men sliter med problemer som dårlig lesbarhet og språkmiksing.
-
DeepSeek-R1: For å adressere begrensningene til DeepSeek-R1-Zero, innlemmer DeepSeek-R1 en flertrinns treningspipeline. Denne pipelinen inkluderer: (a) en kaldstartfase ved hjelp av en liten mengde menneskelig kuraterte data for å finjustere en basismodell (DeepSeek-V3-Base); (b) resonneringsorientert RL ved hjelp av GRPO, lik DeepSeek-R1-Zero, men med en belønning for språklig konsistens; (c) avvisningsutvalg og overvåket finjustering for å generere data av høyere kvalitet for et påfølgende RL-stadium; og (d) et siste RL-stadium som innlemmer prompter fra ulike scenarioer for å forbedre modellens hjelpsomhet og harmløshet.
De viktigste funnene er at DeepSeek-R1 oppnår ytelse sammenlignbar med OpenAIs o1-1217 på ulike resonneringsbenchmark, og signifikant overgår DeepSeek-R1-Zero og andre eksisterende modeller på flere oppgaver. DeepSeek-R1 viser sterk ytelse på tvers av ulike oppgaver, inkludert matematikk, koding og sunn fornuft-resonnering, og overgår til og med OpenAI-01-1217 på noen benchmark. Videre demonstrerer forskerne effektiviteten av å destillere kunnskapen fra DeepSeek-R1 til mindre, mer effektive tette modeller (ved hjelp av Qwen og Llama), og oppnår state-of-the-art ytelse på flere benchmark.
Implikasjonene av denne forskningen er betydelige. Suksessen til DeepSeek-R1, spesielt dens sammenlignbare ytelse med OpenAIs o1-1217 uten å være sterkt avhengig av SFT, tyder på et potensielt skifte i LLM-treningsparadigmer. Den foreslåtte flertrinns pipelinen tilbyr en mer effektiv og skalerbar tilnærming til trening av LLMer med forbedret resonneringsevne. I tillegg fremhever suksessen med kunnskapsdestillasjon det potensialet for å skape kraftige, men ressurseffektive, resonneringsmodeller ved å overføre kunnskap fra større modeller. Åpen kildekode-tilgjengeligheten av DeepSeek-R1-Zero, DeepSeek-R1 og de destilerte modellene vil tillate det bredere forskningsmiljøet å bygge videre på dette arbeidet og bidra til ytterligere fremskritt innen LLM-resonnering. Artikkelen anerkjenner også begrensninger, inkludert språkmiksing og følsomhet for prompt-konstruksjon, noe som tyder på områder for fremtidig forskning og utvikling.